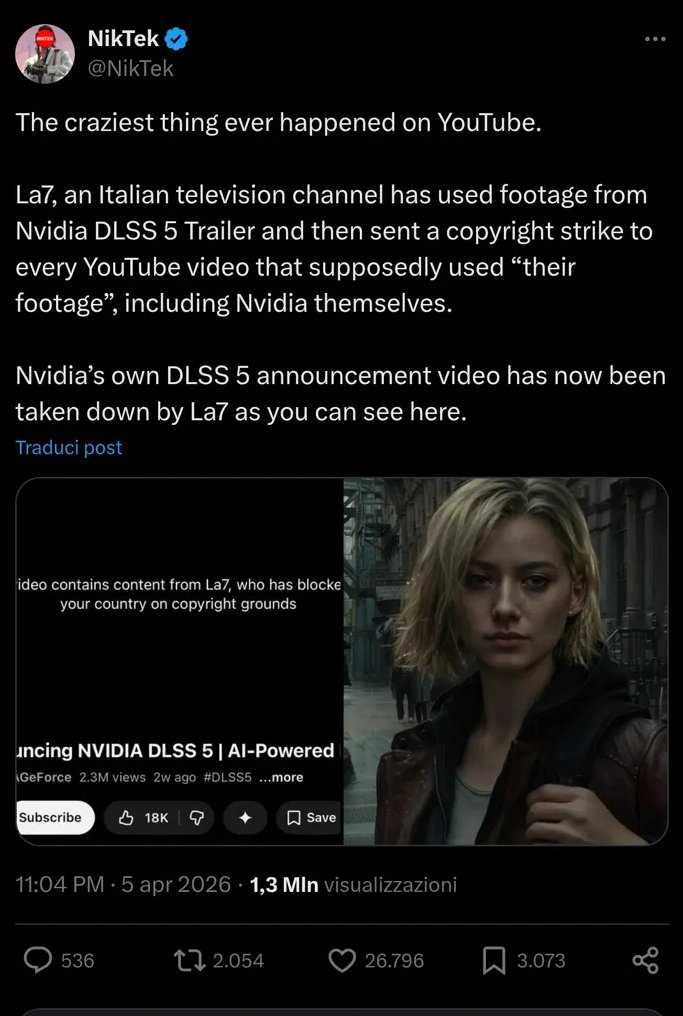
L'utente NikTek segnala su X, con 1,3 milioni di visualizzazioni in poche ore, una cosa apparentemente impossibile: Nvidia non riesce a tenere online il proprio video di annuncio su YouTube perché un canale televisivo italiano lo ha rimosso. Il video in questione è il trailer del DLSS 5, la tecnologia di rendering AI presentata durante la GTC 2026, che aveva già superato i 2,3 milioni di visualizzazioni prima di sparire dalla piattaforma.
La spiegazione ufficiale non è arrivata. Quello che si sa è che il canale La7 avrebbe registrato nel sistema Content ID di YouTube delle impronte digitali ricavate da quel filmato, attivando rimozioni automatiche a catena su tutti i video che contenevano le stesse sequenze. Come ci si sia arrivati, però, è ancora poco chiaro. Forse un dipendente inesperto ha caricato nel sistema materiale altrui senza verificarne la provenienza. Forse l'automazione ha reagito in modo aggressivo a input ambigui. Forse qualcuno, in buona fede, ha tratto conclusioni troppo rapide senza avere abbastanza elementi davanti. Probabilmente, anche in azienda, nessuno lo sa con precisione. E questo dato è più interessante della vicenda in sé.
Il caso fornisce l'occasione per guardare più da vicino come funziona davvero un sistema che decide, ogni giorno, chi può pubblicare cosa su una delle piattaforme più grandi del mondo. Un tema che, tra l'altro, si intreccia con questioni simili già emerse in vicende come quella tra SIAE e Meta, dove il diritto d'autore digitale ha mostrato tutta la sua asimmetria.
Come funziona Content ID
Content ID è il sistema di riconoscimento automatico dei contenuti protetti da copyright che YouTube ha sviluppato a partire dal 2007. Il meccanismo di base è quello delle impronte digitali: chi detiene i diritti su un'opera carica nel sistema dei file di riferimento, il software crea un fingerprint univoco, e ogni video caricato sulla piattaforma viene confrontato in automatico con quel database. Se c'è corrispondenza, il sistema agisce: può bloccare il video, monetizzarlo a favore del titolare, o limitarne la visibilità geografica. Tutto senza che nessun essere umano intervenga.
Il problema strutturale è uno: il sistema non verifica chi ha creato il contenuto originale. Non controlla le date di pubblicazione. Non sa che quel video esisteva prima che qualcuno lo ritrasmettesse in televisione. Confronta un fingerprint con una voce nel database e applica la policy associata. Come segnalato da creator colpiti dalla stessa ondata di rimozioni, tra cui TheDezemBro e Destin Legarie, video pubblicati settimane prima della messa in onda televisiva sono stati rimossi lo stesso. Destin Legarie ha caricato il suo video il 16 marzo 2026. La7 avrebbe trasmesso le immagini il 4 aprile 2026. Il copyright strike è arrivato comunque, perché il sistema non legge la cronologia.
Il sistema non verifica chi ha creato il contenuto. Confronta un fingerprint con il database e agisce. Chi ha inserito il fingerprint per primo, vince.
Perché più controllo umano non risolve
La risposta automatica di fronte a questi episodi è sempre la stessa: ci vorrebbe più supervisione umana. È comprensibile. Ma il problema è più sottile.
Un revisore che valuta un reclamo ha accesso a informazioni limitate: non sa necessariamente che quel materiale era già online, non può verificare facilmente chi lo ha prodotto per primo, non conosce la storia di ogni singolo upload su una piattaforma che riceve oltre 500 ore di video al minuto. Secondo dati riportati dalla Electronic Frontier Foundation, il 98 percento delle rivendicazioni di copyright su YouTube è gestito da Content ID senza alcun intervento umano. Non perché nessuno abbia pensato ai rischi, ma perché non esistono le risorse per fare diversamente a quella scala.
Il risultato concreto è che il sistema favorisce strutturalmente chi arriva per primo con una rivendicazione. Non chi ha ragione sul merito. Chi ha inserito il fingerprint nel database prima che qualcun altro potesse contestarlo.
Una asimmetria che non è un errore
Vale la pena soffermarsi su un aspetto che passa spesso in secondo piano. L'accesso a Content ID non è simmetrico. Le grandi emittenti televisive, i major label musicali, gli studios cinematografici hanno accesso diretto al sistema e possono caricare riferimenti nel database in modo massiccio. I creator indipendenti, in molti casi, non possono nemmeno richiedere l'accesso direttamente e devono passare attraverso intermediari certificati. Non è un'eccezione: è una scelta progettuale deliberata. Chi produce contenuti in grande volume ha più potere di rivendicazione, indipendentemente da chi abbia effettivamente creato cosa.
Non c'è nulla di formalmente illecito in questa struttura. Ma vale la pena chiedersi se un sistema di tutela del diritto d'autore che avvantaggia strutturalmente i grandi soggetti rispetto ai singoli creator stia davvero tutelando i diritti, o stia tutelando il potere di chi può permettersi di usarlo. Non è una domanda nuova: è la stessa che emerge ogni volta che si parla di intelligenza artificiale e proprietà intellettuale, dove le asimmetrie tra grandi piattaforme e soggetti individuali sono strutturali per definizione.
Il copyright come leva, non come principio
Senza attribuire intenti specifici alla vicenda in esame, di cui la ricostruzione completa non è ancora disponibile, c'è una dinamica più generale che questo episodio porta in superficie. Il meccanismo di Content ID, per come è costruito, può essere impiegato come strumento di pressione: basta registrare un fingerprint in anticipo, o registrarne abbastanza da colpire un volume elevato di contenuti, per ottenere effetti rilevanti sulla visibilità altrui. Non è necessario avere ragione sul merito. È necessario muoversi per primi.
Viene segnalato da più osservatori che questa dinamica non sia isolata. I casi documentati di rivendicazioni errate o abusive su YouTube sono numerosi. I creator più piccoli, quelli senza le risorse per contestare sistematicamente ogni strike nel meccanismo di dispute previsto dalla piattaforma, spesso cedono. Non perché abbiano torto, ma perché il costo di dimostrare di avere ragione è semplicemente troppo alto rispetto al beneficio.
Tutto questo pone una domanda che va oltre la vicenda Nvidia. Stiamo delegando decisioni con rilevanza giuridica concreta a sistemi automatizzati che non dispongono degli strumenti per prenderle in modo accurato. Lo facciamo perché non esiste un'alternativa praticabile alla scala attuale. Ma forse vale la pena chiedersi se il prezzo di quella scala non ricada in modo sproporzionato su chi ha meno voce per contestarla.